The-Art-of-Problem-Solving-in-Software-Engineering_How-to-Make-MySQL-Better
4.9 Distributed Theory
A MySQL cluster functions as a distributed database, governed by principles of distributed theory such as the CAP theorem and consistency.
4.9.1 CAP Theorem
A distributed database has three very desirable properties:
1. Tolerance towards Network Partition
2. Consistency
3. Availability
The CAP theorem states: You can have at most two of these properties for any shared-data system
Theoretically there are three options:
-
Forfeit Partition Tolerance
The system does not have a defined behavior in case of a network partition.
-
Forfeit Consistency
In case of partition data can still be used, but since the nodes cannot communicate with each other there is no guarantee that the data is consistent.
-
Forfeit Availability
Data can only be used if its consistency is guaranteed, which implies the need for pessimistic locking. This requires locking any updated object until the update has been propagated to all nodes. In the event of a network partition, it may take a considerable amount of time for the database to return to a consistent state, thereby compromising the guarantee of high availability.
Forfeiting Partition Tolerance is not feasible in realistic environments, as network partitions are inevitable. Therefore, it becomes necessary to make a choice between Availability and Consistency [20].
The proof process of the CAP theorem is a typical example of logical reasoning. The specific proof process is described below [20]:
First Gilbert and Lynch defined the three properties:
1. Consistency (atomic data objects)
A total order must exist on all operations such that each operation looks as if it were completed at a single instance. For distributed shared memory this means (among other things) that all read operations that occur after a write operation completes must return the value of this (or a later) write operation.
2. Availability
Every request received by a non-failing node must result in a response. This means, any algorithm used by the service must eventually terminate.
3. Partition Tolerance
The network is allowed to lose arbitrarily many messages sent from one node to another.
With this definition, the theorem was proven by contradiction:
Assume all three criteria (atomicity, availability and partition tolerance) are fulfilled. Since any network with at least two nodes can be divided into two disjoint, non-empty sets {G1,G2}, we define our network as such. An atomic object o has the initial value v0. We define a1 as part of an execution consisting of a single write on the atomic object to a value v1 ≠ v0 in G1. Assume a1 is the only client request during that time. Further, assume that no messages from G1 are received in G2, and vice versa.
Because of the availability requirement we know that a1 will complete, meaning that the object o now has value v1 in G1.
Similarly a2 is part of an execution consisting of a single read of o in G2. During a2 again no messages from G2 are received in G1 and vice versa. Due to the availability requirement we know that a2 will complete.
If we start an execution consisting of a1 and a2, G2 only sees a2 since it does not receive any messages or requests concerning a1. Therefore the read request from a2 still must return the value v0. But since the read request starts only after the write request ended, the atomicity requirement is violated, which proves that we cannot guarantee all three requirements at the same time. q.e.d.
Understanding the CAP theorem lays a foundation for comprehending problems in distributed systems. For instance, in a Group Replication cluster, achieving strong consistency on every node may require sacrificing availability. The “after” mechanism of Group Replication can meet this requirement. Conversely, prioritizing availability means that during network partitions, MySQL secondaries might read stale data since distributed consistency in reads cannot be guaranteed.
4.9.2 Read Consistency
MySQL secondaries can handle read tasks, but they may not keep up with the pace of the MySQL primary. This can lead to problems with read consistency.
In a distributed environment, the paper “Replicated Data Consistency Explained Through Baseball” [37] describes various types of read operation consistency. Below is a detailed outline of common types of read operation consistency.
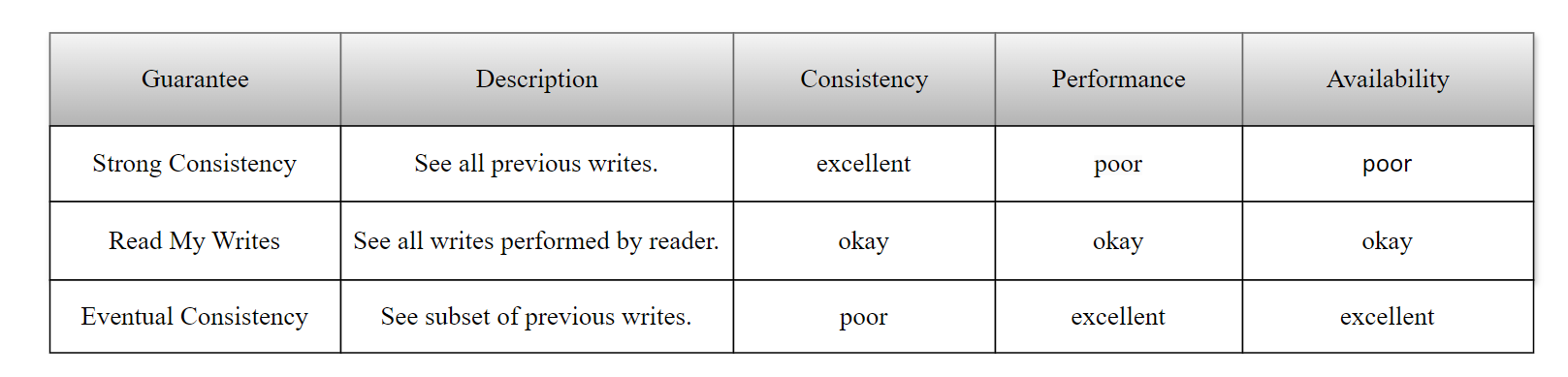
Figure 4-67. Common types of read operation consistency.
The figure describes the three most common types of consistency: strong consistency, read-your-writes consistency, and eventual consistency. The pattern observed is that the stronger the consistency, the poorer the performance, and the lower the availability.
When reading data from multiple MySQL secondaries, various consistency read problems can easily arise. These can be mitigated using MySQL proxies. For instance, for the same user session, read operations can be directed to a single MySQL secondary. If the data on that MySQL secondary is not up-to-date, the operation waits, thus avoiding typical consistency read problems.
MySQL has made significant efforts to ensure consistent reads in clustered environments. During MySQL secondary replay, it is crucial to maintain the transaction commit order consistent with the relay log entry order. This means that a transaction can only commit once all preceding transactions have been committed. The replica_preserve_commit_order parameter in MySQL helps enforce this constraint.
To effectively mitigate consistency read problems, MySQL secondaries should ideally keep up with the pace of the MySQL primary. If the MySQL primary and its secondaries operate at similar speeds, users can quickly access the most recent data from the secondaries. Therefore, combining fast replay on MySQL secondaries with addressing consistency read problems can significantly ease these challenges.
4.9.3 Consensus
For decades, the Paxos algorithm has been synonymous with distributed consensus. Despite its widespread deployment in production systems, Paxos is often misunderstood and proves to be heavyweight, unscalable, and unreliable in practice. Extensive research has been conducted to better understand the algorithm, optimize its performance, and mitigate its limitations [29]. Over time, numerous variants of Paxos have emerged, each tailored to different application scenarios based on majority-based consensus. It is important to keep these variants distinct.
For example, Group Replication in MySQL supports both single-primary and multi-primary modes, requiring consistent read and write operations in single-primary mode. This necessitates a multi-leader Paxos algorithm for consensus. The MySQL’s original Mencius algorithm faced performance problems in certain scenarios, leading to the introduction of a single-leader Multi-Paxos algorithm to address these concerns. Maintaining two different variants of the Paxos algorithm simultaneously poses challenges in code maintenance, and numerous regression problems discovered later have validated this viewpoint.
4.9.4 Distributed Transaction
In MySQL, the XA protocol can be used to implement the two-phase commit protocol, ensuring atomicity in distributed environments. Many database products use XA to implement distributed transactions with various transaction isolation levels. However, response times in this context are often not ideal.
As highlighted in “Designing Data-Intensive Applications” [28]: “XA has poor fault tolerance and performance characteristics, which severely limit its usefulness.” MySQL XA transactions not only negatively impact response times but also pose challenges for MySQL secondary replay. The second phase of an XA transaction depends on the first phase, affecting concurrent replay on MySQL secondaries, as different phases must proceed serially.
Therefore, it is advisable for MySQL users to avoid XA transactions when possible. It’s important to note that while the XA two-phase commit protocol bears some similarities to Paxos algorithms, the XA protocol cannot utilize batching techniques and requires all participants to agree before proceeding with subsequent operations.